- Discriminative model vs Generative Model
분류(Classification) 문제는 크게 Generative model과 discriminative model로 나눌 수 있는데, 로지스틱 회귀분석(logistic regression)처럼 클래스를 분류하는데 집중하는 모델들이 discriminative model이며, 반면에 generative model은 우도(likelihood)나 사후 확률(posterior probability)를 사용하여 분류 경계선(decision boundary)를 만든다고 알려져 있다.
(그런데, 사실 어떤 모델을 사용한다고 했을때, 그 모델 자체를 분류 모델 or 생성 모델로 구분해서 보는 것이 애매하다고 생각이든다. 왜냐하면 보통 학습을 할때 Pre-Trained된 모델을 사용해서 다양한 Downstream Task에 적용하는 경우가 많기 때문에, Task에 따라서 사용성이 결정되는 모델들이 많아서 어떤 특정 모델은 무조건 생성 모델이다! 분류모델이다! 나눠서 구분하는게 크게 중요하진 않은것같다.)
그래도 생성모델과 분류모델의 이해를 위해 간단하게 설명하면, discriminative model은 클래스의 차이점에 주목하는 것이고 generative model은 클래스의 분포에 주목한다고 생각하면 된다.
생성모델은 주어진 학습 데이터를 학습하여 학습 데이터의 분포를 따르는 유사한 데이터를 생성하는 모델이다. 학습 데이터와 유사한 샘플을 뽑아야하기 때문에, 생성 모델에는 학습 데이터의 분포를 어느 정도 안 상태에서 생성하거나(Explicit) 잘 모르지만 그럼에도 생성(Implicit)하는 다양한 모델들이 존재한다. 학습 데이터 속에는 각 샘플들마다 픽셀들의 분포를 알 수 있다. 이러한 분포들만 제대로 알아낼 수 있다면 완전히 동일하진 않지만, 어느 정도 학습 데이터와 유사한 데이터를 생성할 수 있다.
즉, 생성모델에서 가장 중요한 것은 학습 데이터의 분포를 학습하는 것이 제일 중요하다.

(예 : 이미지 생성(DALL-E), 목소리 재현(VALL-E), 텍스트 생성(ChatGPT), 데이터의 이상치 탐지, 텍스트 기반 비디오 생성 등등..)
- Generative Model 종류
생성모델이 학습데이터와 유사한 샘플을 뽑는 방법에는 여러 방식들이 있는데, 대표적으로 학습 데이터의 분포를 기반으로 할 것인지(Explicit density) 혹은 그러한 분포를 몰라도 샘플링을 반복하여 특정 확률 분포에 수렴시키는 모델(Implicit density)로 나뉜다.
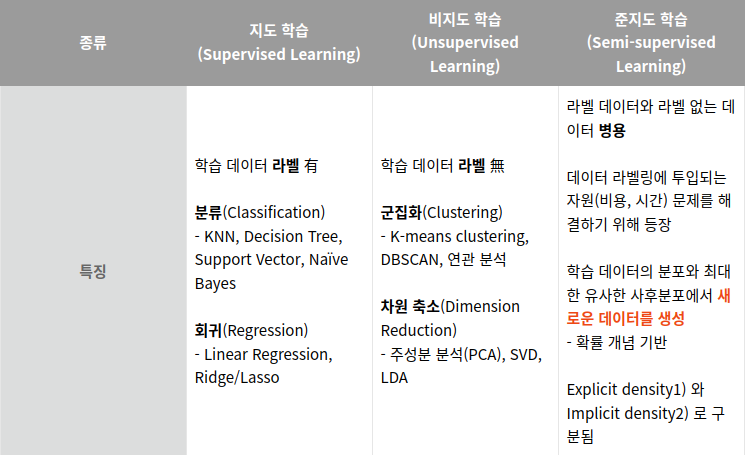
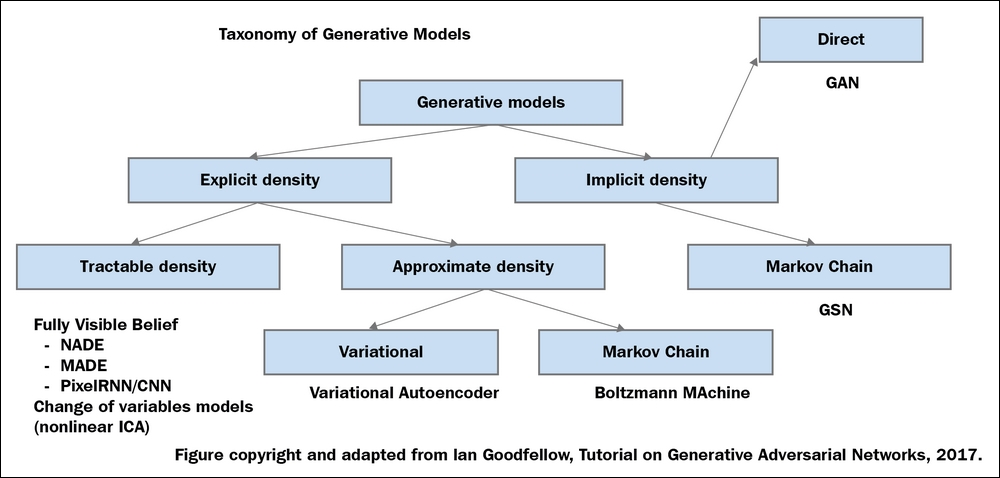
| Model | 특징 | 예시 |
| Explicit density | Tractable density – 모델의 사전분포를 가정하여 기존 값으로부터 데이터 분포를 추정 | Full Visible Belief Nets – NADE – MADE – PixelRNN/CNN |
| Explicit density | Approximate density – 모델의 사전분포를 근사시켜 데이터 분포를 추정 | VAE Markov Chain (Boltzmann Machine) |
| Implicit density | 데이터의 확률 분포를 모르는 상태 (즉 모델이 명확히 정의되어 있지 않은 대신)에서 샘플링을 반복하여 특정 확률 분포에 수렴시킴으로서 추정하는 모델 | GAN Markov Chain (GSN) |
1) Auto-regressive models(ARMs)
순서를 가지는 변수(variable)들의 조건부 확률(conditional probability)의 곱으로 데이터의 likelihood를 계산하는 모델이다. 주어진 데이터의 likelihood를 계산할 수 있는 장점은 있지만 sampling이 느리고, 데이터에 내재된 잠재형상(latent feature)은 학습할 수 없는 단점이 있다.
2) Variational Auto encoders(VAEs)
잠재변수(Latent variable)기반의 generative model로 데이터 x와 latent variable z의 결합확률분포(joint distribution)를 구해서 x에 대해서 주변화(marginalize)하는 모델이다. 빠른 학습과 sampling, 데이터의 latent feature 학습이 가능한 장점과, likelihood를 다루기 힘들고 사전확률(prior distribution)이 한정적이라는 단점이 있다.
3) Energy Based Models(EBMs)
에너지함수(Energy function)를 이용해서 distribution을 estimate한다. 제약(Constraint)이 없어 간편하다는 장점이 있으나, likelihood와 sampling이 다루기 힘들다는 단점이 있다.
4) Generative Adversarial Networks(GANs)
Discriminator와 Generator를 서로 adversarial 방향으로 학습시켜서 데이터를 생성하는 모델이다. Sample quality가 좋고, fast training과 fast sampling이 가능한 장점이, likelihood가 define되지 않고 unstable training이 단점이 있다.
5) Normalizing Flows
Simple한 base 분포 p(z)에서 복잡한 데이터 분포 p(x)로 가는 역사상(invertible mapping)함수를 이용해 distribution을 estimate하는 모델이다. Exact likelihood 값을 계산할 수 있고, fast sampling이 가능하나, architecture에서 제한 조건이 부여된다는 단점이 있다.
6) Diffusion
데이터 x에서 점점 noise를 추가해서 noise data로 만들고, noise data에서 데이터 x로 돌아오는 과정을 학습해 distribution을 estimate하는 모델이다. Likelihood는 다루기 힘들지만 좋은 likelihood 값을 가지고 특별한 제한 조건 없이 complex distribution을 잘 estimate하는 특징이 있다.
[NeurIPS 2021] 1편: Generative model - Diffusion model Review - LG AI Research BLOG
www.lgresearch.ai
https://minsuksung-ai.tistory.com/12
생성모델(Generative model)이란 무엇일까?
내일이 기말고사라서 간단하게 강의 정리도 해야해서, 오늘은 비지도학습(Unsupervised learning) 중에서 클러스터링(Clustering)과 함께 가장 대표적인 예시 중 하나인 생성모델(Generative model)에 관련해
minsuksung-ai.tistory.com
https://danbi-ncsoft.github.io/works/2021/10/01/Generator.html
생성모델(Generation Model)이란 무엇인가?
danbi-ncsoft.github.io
https://newstellar.tistory.com/25
[인공지능] 생성 모델 (Generative AI Model)이란? (1) : AutoEncoder, VAE, GAN
학습목표 1. 지도/비지도/준지도 학습의 특징을 구분할 수 있습니다. 2. 생성 모델의 대표적인 두 모델(VAE 및 GAN)의 차이점을 알게 됩니다. 3. GAN의 활용 범위에 대해 말할 수 있습니다. 생성 모델 (
newstellar.tistory.com
https://kimchihill.com/2022/08/31/kr-generative-ai-is-the-future/
역시 생성모델 (Generative AI)이 미래다 - Kimchi hill
가트너가 ‘2022년 이머징 테크놀로지 하이프 사이클 (Hype Cycle for Emerging Technologies, 2022)’보고서를 발표하며, AI 자동화 및 가속화가 중요한 화두이며, 이를 위해 주목해야 할 기술로 제너레이티
kimchihill.com
https://deepdaiv.oopy.io/d21d2180-a7f2-4397-95a7-fa183d9c6b86
Generative AI, 생성 모델 톺아보기(1) - GAN
INTRO
deepdaiv.oopy.io
'전체보기 > Generative Model' 카테고리의 다른 글
| Generative Model - VAE(Variational AutoEncoder) (0) | 2023.07.28 |
|---|
- Discriminative model vs Generative Model
분류(Classification) 문제는 크게 Generative model과 discriminative model로 나눌 수 있는데, 로지스틱 회귀분석(logistic regression)처럼 클래스를 분류하는데 집중하는 모델들이 discriminative model이며, 반면에 generative model은 우도(likelihood)나 사후 확률(posterior probability)를 사용하여 분류 경계선(decision boundary)를 만든다고 알려져 있다.
(그런데, 사실 어떤 모델을 사용한다고 했을때, 그 모델 자체를 분류 모델 or 생성 모델로 구분해서 보는 것이 애매하다고 생각이든다. 왜냐하면 보통 학습을 할때 Pre-Trained된 모델을 사용해서 다양한 Downstream Task에 적용하는 경우가 많기 때문에, Task에 따라서 사용성이 결정되는 모델들이 많아서 어떤 특정 모델은 무조건 생성 모델이다! 분류모델이다! 나눠서 구분하는게 크게 중요하진 않은것같다.)
그래도 생성모델과 분류모델의 이해를 위해 간단하게 설명하면, discriminative model은 클래스의 차이점에 주목하는 것이고 generative model은 클래스의 분포에 주목한다고 생각하면 된다.
생성모델은 주어진 학습 데이터를 학습하여 학습 데이터의 분포를 따르는 유사한 데이터를 생성하는 모델이다. 학습 데이터와 유사한 샘플을 뽑아야하기 때문에, 생성 모델에는 학습 데이터의 분포를 어느 정도 안 상태에서 생성하거나(Explicit) 잘 모르지만 그럼에도 생성(Implicit)하는 다양한 모델들이 존재한다. 학습 데이터 속에는 각 샘플들마다 픽셀들의 분포를 알 수 있다. 이러한 분포들만 제대로 알아낼 수 있다면 완전히 동일하진 않지만, 어느 정도 학습 데이터와 유사한 데이터를 생성할 수 있다.
즉, 생성모델에서 가장 중요한 것은 학습 데이터의 분포를 학습하는 것이 제일 중요하다.
(예 : 이미지 생성(DALL-E), 목소리 재현(VALL-E), 텍스트 생성(ChatGPT), 데이터의 이상치 탐지, 텍스트 기반 비디오 생성 등등..)
- Generative Model 종류
생성모델이 학습데이터와 유사한 샘플을 뽑는 방법에는 여러 방식들이 있는데, 대표적으로 학습 데이터의 분포를 기반으로 할 것인지(Explicit density) 혹은 그러한 분포를 몰라도 샘플링을 반복하여 특정 확률 분포에 수렴시키는 모델(Implicit density)로 나뉜다.
| Model | 특징 | 예시 |
| Explicit density | Tractable density – 모델의 사전분포를 가정하여 기존 값으로부터 데이터 분포를 추정 | Full Visible Belief Nets – NADE – MADE – PixelRNN/CNN |
| Explicit density | Approximate density – 모델의 사전분포를 근사시켜 데이터 분포를 추정 | VAE Markov Chain (Boltzmann Machine) |
| Implicit density | 데이터의 확률 분포를 모르는 상태 (즉 모델이 명확히 정의되어 있지 않은 대신)에서 샘플링을 반복하여 특정 확률 분포에 수렴시킴으로서 추정하는 모델 | GAN Markov Chain (GSN) |
1) Auto-regressive models(ARMs)
순서를 가지는 변수(variable)들의 조건부 확률(conditional probability)의 곱으로 데이터의 likelihood를 계산하는 모델이다. 주어진 데이터의 likelihood를 계산할 수 있는 장점은 있지만 sampling이 느리고, 데이터에 내재된 잠재형상(latent feature)은 학습할 수 없는 단점이 있다.
2) Variational Auto encoders(VAEs)
잠재변수(Latent variable)기반의 generative model로 데이터 x와 latent variable z의 결합확률분포(joint distribution)를 구해서 x에 대해서 주변화(marginalize)하는 모델이다. 빠른 학습과 sampling, 데이터의 latent feature 학습이 가능한 장점과, likelihood를 다루기 힘들고 사전확률(prior distribution)이 한정적이라는 단점이 있다.
3) Energy Based Models(EBMs)
에너지함수(Energy function)를 이용해서 distribution을 estimate한다. 제약(Constraint)이 없어 간편하다는 장점이 있으나, likelihood와 sampling이 다루기 힘들다는 단점이 있다.
4) Generative Adversarial Networks(GANs)
Discriminator와 Generator를 서로 adversarial 방향으로 학습시켜서 데이터를 생성하는 모델이다. Sample quality가 좋고, fast training과 fast sampling이 가능한 장점이, likelihood가 define되지 않고 unstable training이 단점이 있다.
5) Normalizing Flows
Simple한 base 분포 p(z)에서 복잡한 데이터 분포 p(x)로 가는 역사상(invertible mapping)함수를 이용해 distribution을 estimate하는 모델이다. Exact likelihood 값을 계산할 수 있고, fast sampling이 가능하나, architecture에서 제한 조건이 부여된다는 단점이 있다.
6) Diffusion
데이터 x에서 점점 noise를 추가해서 noise data로 만들고, noise data에서 데이터 x로 돌아오는 과정을 학습해 distribution을 estimate하는 모델이다. Likelihood는 다루기 힘들지만 좋은 likelihood 값을 가지고 특별한 제한 조건 없이 complex distribution을 잘 estimate하는 특징이 있다.
[NeurIPS 2021] 1편: Generative model - Diffusion model Review - LG AI Research BLOG
www.lgresearch.ai
https://minsuksung-ai.tistory.com/12
생성모델(Generative model)이란 무엇일까?
내일이 기말고사라서 간단하게 강의 정리도 해야해서, 오늘은 비지도학습(Unsupervised learning) 중에서 클러스터링(Clustering)과 함께 가장 대표적인 예시 중 하나인 생성모델(Generative model)에 관련해
minsuksung-ai.tistory.com
https://danbi-ncsoft.github.io/works/2021/10/01/Generator.html
생성모델(Generation Model)이란 무엇인가?
danbi-ncsoft.github.io
https://newstellar.tistory.com/25
[인공지능] 생성 모델 (Generative AI Model)이란? (1) : AutoEncoder, VAE, GAN
학습목표 1. 지도/비지도/준지도 학습의 특징을 구분할 수 있습니다. 2. 생성 모델의 대표적인 두 모델(VAE 및 GAN)의 차이점을 알게 됩니다. 3. GAN의 활용 범위에 대해 말할 수 있습니다. 생성 모델 (
newstellar.tistory.com
https://kimchihill.com/2022/08/31/kr-generative-ai-is-the-future/
역시 생성모델 (Generative AI)이 미래다 - Kimchi hill
가트너가 ‘2022년 이머징 테크놀로지 하이프 사이클 (Hype Cycle for Emerging Technologies, 2022)’보고서를 발표하며, AI 자동화 및 가속화가 중요한 화두이며, 이를 위해 주목해야 할 기술로 제너레이티
kimchihill.com
https://deepdaiv.oopy.io/d21d2180-a7f2-4397-95a7-fa183d9c6b86
Generative AI, 생성 모델 톺아보기(1) - GAN
INTRO
deepdaiv.oopy.io
'전체보기 > Generative Model' 카테고리의 다른 글
| Generative Model - VAE(Variational AutoEncoder) (0) | 2023.07.28 |
|---|