<개인적인 공부를 위해 작성된 글입니다. 오타 혹은 잘못된 부분이 있다면 지적해주시면 감사하겠습니다.>
먼저 내용을 들어가기에 앞서, Loss function에 대해서 짧게 소개하면
Loss Function
Loss function은 Neural Network가 Learning할 수 있도록 해주는 지표입니다. 정답과 출력값의 차이, 즉 오차를 말합니다.
이 오차값을 최소화 하기위한 Loss function 값(=오차) w와 b를 찾습니다.
image를 학습하는데 사용되는 Loss function에는 대표적으로 Binary Loss, Triplet loss, Contrastive Loss 등이 있는데,
오늘 소개할건 Contrastive Loss의 Generalized된 내용이다.
1. INTRODUCTION
- Place recognition
그러나 두 image 간의 Similar는 binary [0, 1]이 아닌 Continuous (0 ~ 1)한 값이라는 것이 본 논문의 keyword이다. Continuous value에 따라서 image를 rank별로 나누어 Learning시키는 function이 바로 Generalized Contrastive Loss function(=GCL)이다.
실험에서는 Siamese network를 사용하는데, 이 Siamese network를 효과적으로 효과적으로 training하기 위한 Loss Function으로 GCL을 제시하고 있다.
- Weak 2D Field-of-View overlap
- Strong 2D Field-of-View overlap
- 3D Field-of-View overlap
위의 세 가지 strategy에 대해서는 뒤에서 설명을 하도록 하겠다.
2. Related Work
추후에 추가할 예정
3. METHODOLOGY
3.1 Fully convolutional backbone and pooling
아래 그림을 보면 Siamese Network를 사용해서 두 Network의 가중치가 공유되는 것을 확인할 수 있다.
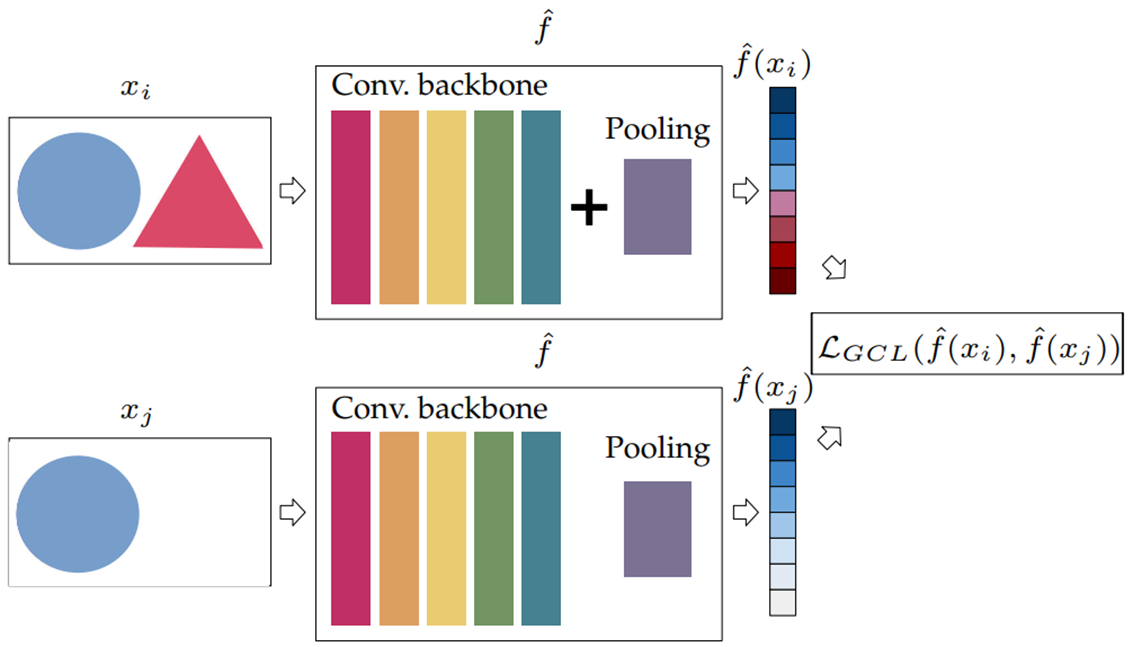
Input images : x_i , x_j
Input Representation : f ̂(x_i), f ̂(x_j)
1. Convolution : DenseNet, ResNet, VGG16 및 ResNeXt를 사용
2. Pooling layer : Global Average Pooling, Generalized Mean Pooling(=GeM)
Siamese architecture의 training : Generalized Contrastive Loss function로 최적화로 진행된다.
다시 정리하면, Siamese Network에 x_i, x_j라는 두 input image가 들어가게 되고, Conv, Pooling layer를 지나서 나온 Embedding된 두 Vector의 Euclidean distance의 차를 구해 GCL로 Learning을 시키는 것이다.
3.2 Generalized Contrastive Loss
Generalized Contrastive Loss를 먼저 보기전에 Contrastive Loss function을 먼저 살펴보겠습니다.
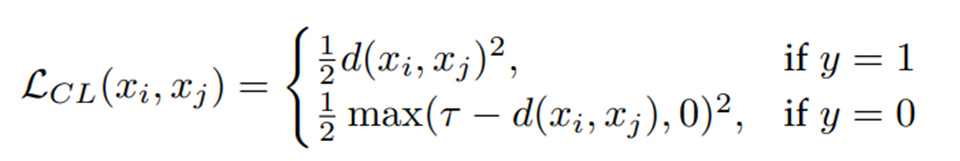
τ : margin , margin은 negative pair간의 최소한의 거리를 의미
Distance between representation of input images
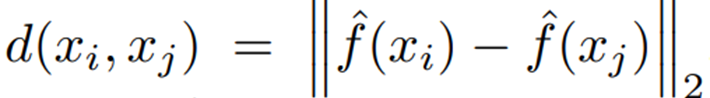
d(x_i, x_j) = Euclidean norm이고, Ground Truth (=y)의 값이 1인경우,
(d(xi, xj)^2)/2의 값이 최소화가 되도록 해야한다. 우선 y=1면 두 image가 similar한 경우이기에,
거의 f(xi) == f(xj)하다. 그러기에 Loss의 값은 0에 수렴하게 될 것이다.
Ground Truth (=y)의 값이 0인경우, 아래 그림을 보자
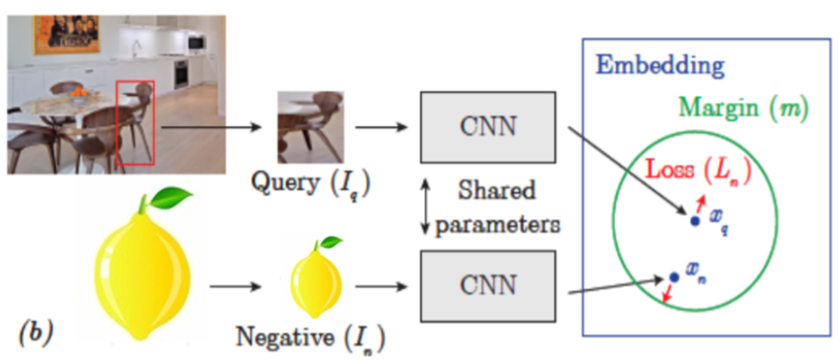
Query image와 Negative image가 주어지면, Negative image는 margin 밖으로 멀어지게 learning이 되어야 한다.
d(xi, xj)의 value가 margin보다 멀리있다면, Negative로 잘 학습이 되고 있다는 것이다.
그러면 식에서 음수 value가 나오게 될 것이고 음수가 나오면 0을 반환을 한다.
그러나 위의 Contrastive Loss function에는 문제가 있다. 아래 3개의 image로 예시를 들어보면,
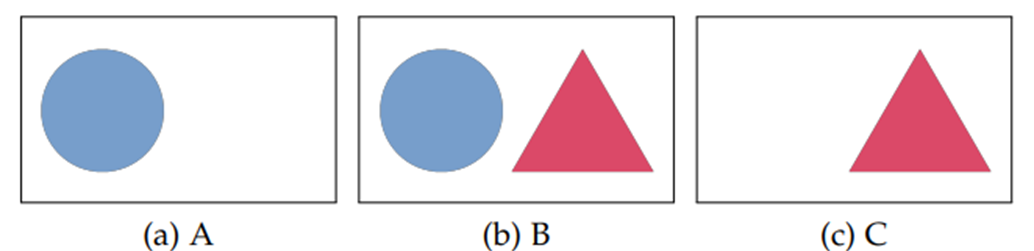
(A, B) -> Similar (y=1) : A와 B는 동그라미 도형의 유사한 부분이 있기에 1
(B, C) -> Similar (y=1) : B와 C는 세모 모형이 유사한 부분이 있기에 1
(A, C) -> Dissimilar (y=0) : A와 C는 공통적인 모형이 없기 때문에 0
Contrastive Loss(대비 손실) 기능의 최적화는 다음과 같이 유사한 영상 쌍(A, B) 및 (B, C)의 표현 사이의 거리를 최소화하는 것을 목적이다.
그러나, 다음 식을 보자.
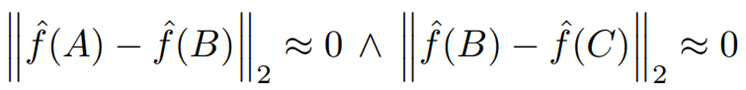
위의 식은 A와 B, B와 C의 유클리드 distance가 0에 가깝다 라고 표현할 수 있다.

그렇기에 A와 B, B와 C의 Embedding vector는 거의 동일하다.
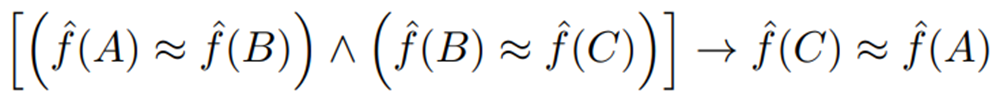
이를 삼단 논법으로 보면, 결국 A와 C도 Similar하다는 결론이 나오게 된다.
위의 예에서는 (A, C)는 다른 라벨로 표시되어 있는데, fig 3의 결과는 fig 1이 보장하는 최적화와 대조적이다.
훈련 프로세스의 이러한 불일치는 Contrastive Loss function이 input pair 간의 부분적인 (Continuous) Similar를 고려하지 않기 때문이다.
그러면 이제 Generalized Contrastive Loss Function을 살펴보자.
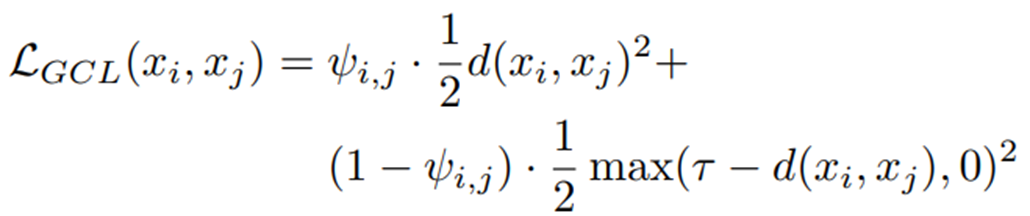
binary보다는 continuous similar를 표현하는 Contrastive Loss의 일반화 공식을 제안
=> Generalized Contrastive Loss (=GCL)
ψ(i,j) : xi, xj 의 similar의 ground truth, 0 ~ 1까지의 Continuous value (0 or 1이 아닌)
Generalized Contrastive Loss 함수를 최소화함으로써 각 pair의 거리는 대응하는 similar에 비례하여 최적화
GCL 함수를 보면, CL함수와 크게 달라진 점은 ψ의 값이 추가된 것이다.
4 TRAINING DATA AND AUTOMATIC LABELLING
Generalized Contrastive Loss(일반화 대조 손실) function의 optimize는 (0 ~ 1) range에서 정의된 영상 쌍의 Ground Truth Similar에 의존
Image pair의 Similar 정도를 자동으로 Labeling하는 세 가지 방법을 제시
2D Field-of-View overlap은 두 가지 measure로 설명한다.
1) Weak Labeled, Relying on GPS data -> Weak 2D Field-of-View overlap,
2) Strongly Labeled, Relying on 6DoF camera pose -> Strong 2D Field-of-View overlap
4.1 2D Field-of-View overlap
=> 수평면에서의 카메라 시야의 중첩만을 고려
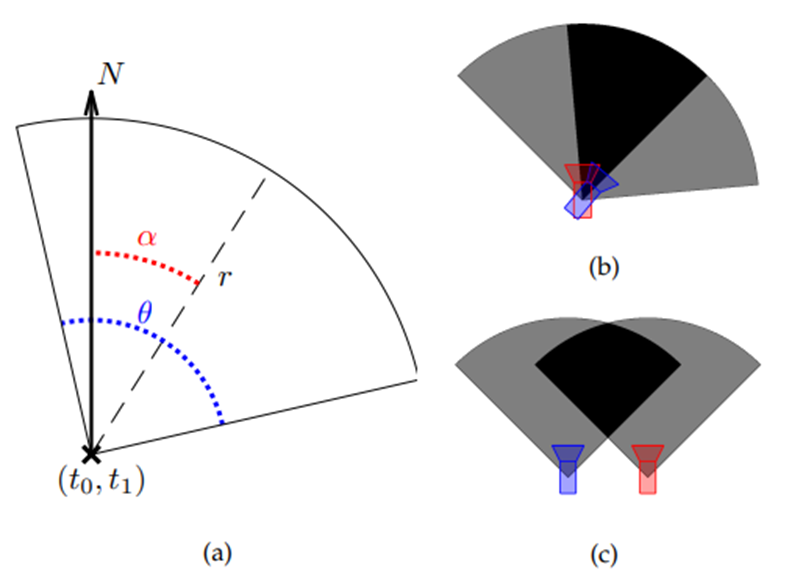
(b) Soft positive match : 같은 위치지만 방향 40°차이
(c) Soft Negative match : 같은 방향, 거리가 다른 경우
4.1.1 Weak 2D Field-of-View overlap

GPS coordinates과 angle 정보를 사용할 수 있는 경우
=> Weak 2D Field-of-View overlap 제시
첫 번째 row은 Query image, 두 번째 row은 map에서 match, 세 번째 row은 estimated 2D FoV overlap
Red -> QR , blue -> map image, 50% 이상이면 positive matching!
4.1.2 Strong 2D Field-of-View overlap
TB-Places dataset 사용

dataset에 image와 함께 6DoF camera pose 정보를 사용할 수 있는 경우
-> Strong 2D Field-of-View overlap을 제시
pose vector로부터 translation vector(t0, t1)와 angle α를 추출
각 이미지에는 매우 정확한 2D FoV를 추정할 수 있는 6DOF 카메라 포즈가 포함
TB-places 데이터 세트의 원본 논문에 따르면, 카메라의 FoV 각도를 90 = 90 µ로, 반지름을 r = 3.5m로 설정
첫 번째 row : 74% positive pair
두 번째 row : 41% Soft negative pair
4.2 3D Field-of-View overlap
7가지 환경에서 촬영한 RGBD image set인 7Scene dataset 사용

3D reconstructure을 사용할 수 있는 경우
각 image는 연관된 6DoF pose를 가지며 각 image의 3D reconstructure가 제공
Point cloud에 6DoF pose와 함께 주어진 image를 projection
Image pair의 경우 두 image와 연관된 3D 지점 세트의 intersection-overunion (IoU)으로 3D FoV overlap을 계산
QR image : red, map : blue, Overlap : magenta
5. Implementation details
5.1 Evaluation metric
6 RESULTS AND DISCUSSION
6.1 Large scale outdoor place recognition
MSLS training set에 관한 몇 가지 모델을 training해, MSLS validation과 test set에 관한 결과를 보고
BackBone : VGG16, ResNet50, ResNet152, ResNeXt101-32x8d
Pooling : global pooling layer, average global pooling
Loss function : binary Contrastive Loss, Generalized Contrastive Loss
BackBone network와 pooling layer의 각 조합에 대해 binary Contrastive Loss, Generalized Contrastive Loss optimize 실행
6.2 Result
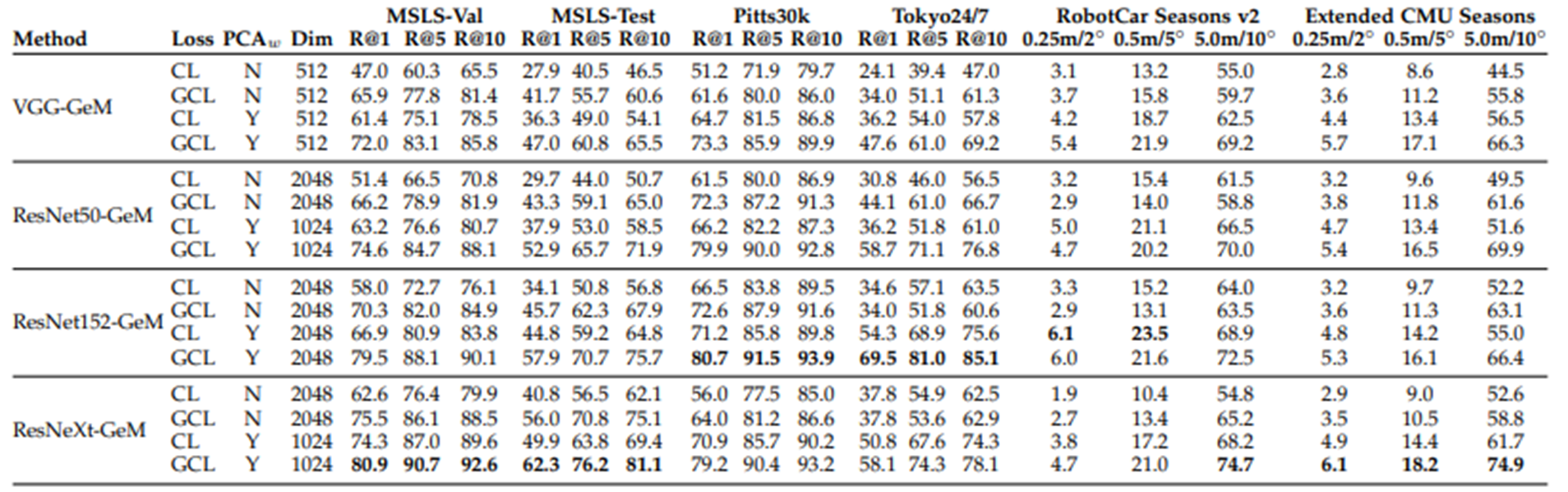
GCL function으로 훈련받은 모델이 CL로 훈련받은 모델보다 일관되게 성능이 우수
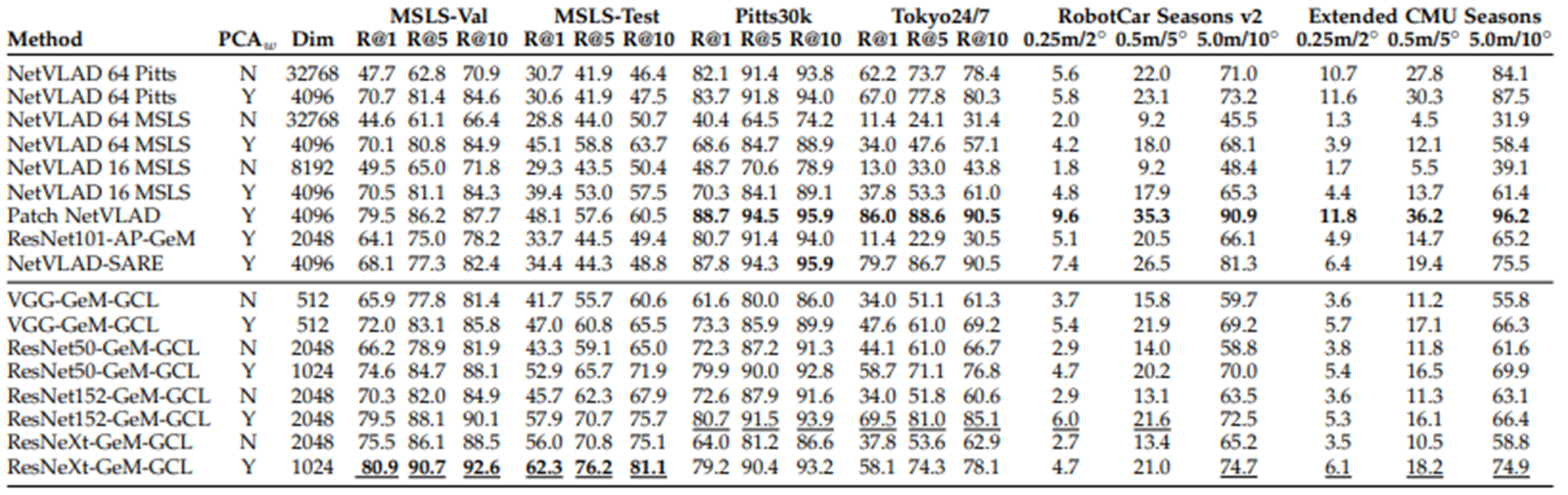
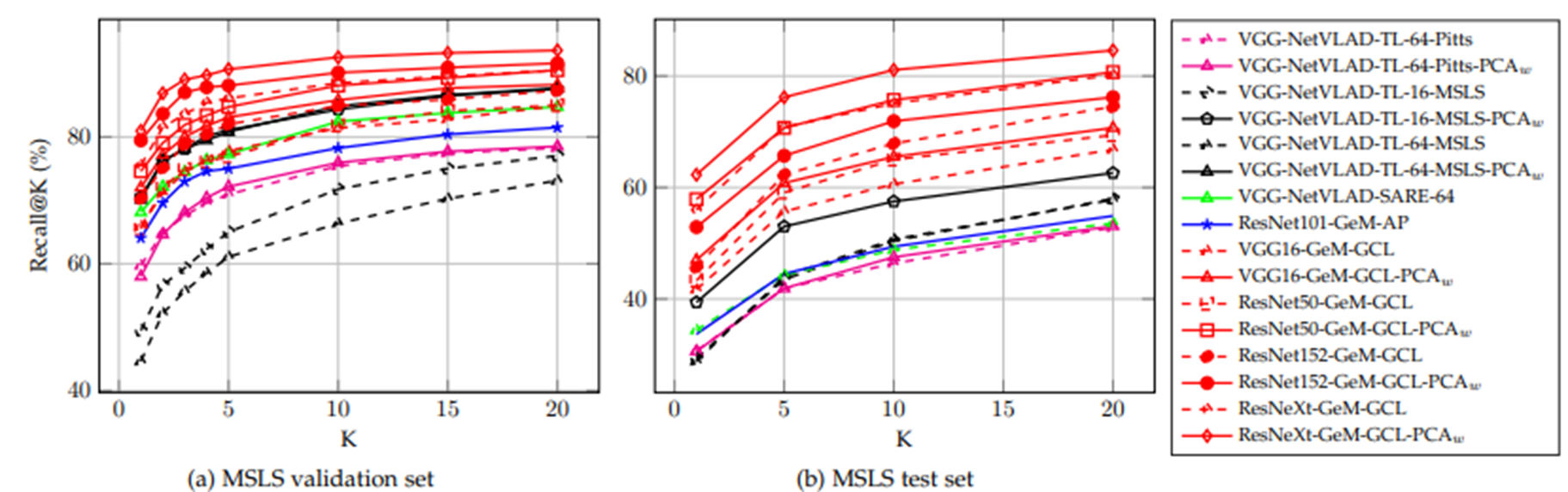
GCL loss function을 사용하여 training한 convolution backbone과 Siamese Network로 배열된 단순한 pooling layer으로만 구성된 단순한 architecture가 triplet network와 VLAD 계층을 배치하는 것처럼 복잡한 architecture보다 뛰어나다는 것을 입증
7 CONCLUSIONS
Image retrieval 및 visual place recognition을 위해 two-way Siamese Network를 효과적으로 training하기 위한 새로운 Generalized Contrastive Loss function를 제시
이 목적을 위해 우리는 image Similar의 Continuous한 Measure을 정의
GPS와 angle, 6DOF camera pose, image 3D 재구성 등 기하학적 정보를 바탕으로 image pair의 Similar estimated을 위한 자동주석 3가지 방식을 구현
MSLS, TB-Places 및 7Scene dataset를 배치하여 binary label이 아닌 rank별 유사성으로 image pair을 제공 (Positive, Soft Negative, Hard Negative)
Re-annotation process는 자동으로 이루어지므로 사람의 개입이 필요하지 않음
제안된 Generalized Contrastive Loss 함수와 rank별 유사성 labeled set를 사용하여 한 네트워크는 MSLS,
TB-Places 및 7Scene 데이터셋에서 binary Contrastive Loss function로 training받은 network보다 지속적으로 더 높은 결과(상위 5개 리콜 최대 18%)를 달성
'Paper' 카테고리의 다른 글
| [논문 리뷰]Siamese Neural Networks for One-shot Image Recognition (2015) (0) | 2022.03.20 |
|---|
<개인적인 공부를 위해 작성된 글입니다. 오타 혹은 잘못된 부분이 있다면 지적해주시면 감사하겠습니다.>
먼저 내용을 들어가기에 앞서, Loss function에 대해서 짧게 소개하면
Loss Function
Loss function은 Neural Network가 Learning할 수 있도록 해주는 지표입니다. 정답과 출력값의 차이, 즉 오차를 말합니다.
이 오차값을 최소화 하기위한 Loss function 값(=오차) w와 b를 찾습니다.
image를 학습하는데 사용되는 Loss function에는 대표적으로 Binary Loss, Triplet loss, Contrastive Loss 등이 있는데,
오늘 소개할건 Contrastive Loss의 Generalized된 내용이다.
1. INTRODUCTION
- Place recognition
그러나 두 image 간의 Similar는 binary [0, 1]이 아닌 Continuous (0 ~ 1)한 값이라는 것이 본 논문의 keyword이다. Continuous value에 따라서 image를 rank별로 나누어 Learning시키는 function이 바로 Generalized Contrastive Loss function(=GCL)이다.
실험에서는 Siamese network를 사용하는데, 이 Siamese network를 효과적으로 효과적으로 training하기 위한 Loss Function으로 GCL을 제시하고 있다.
- Weak 2D Field-of-View overlap
- Strong 2D Field-of-View overlap
- 3D Field-of-View overlap
위의 세 가지 strategy에 대해서는 뒤에서 설명을 하도록 하겠다.
2. Related Work
추후에 추가할 예정
3. METHODOLOGY
3.1 Fully convolutional backbone and pooling
아래 그림을 보면 Siamese Network를 사용해서 두 Network의 가중치가 공유되는 것을 확인할 수 있다.
Input images : x_i , x_j
Input Representation : f ̂(x_i), f ̂(x_j)
1. Convolution : DenseNet, ResNet, VGG16 및 ResNeXt를 사용
2. Pooling layer : Global Average Pooling, Generalized Mean Pooling(=GeM)
Siamese architecture의 training : Generalized Contrastive Loss function로 최적화로 진행된다.
다시 정리하면, Siamese Network에 x_i, x_j라는 두 input image가 들어가게 되고, Conv, Pooling layer를 지나서 나온 Embedding된 두 Vector의 Euclidean distance의 차를 구해 GCL로 Learning을 시키는 것이다.
3.2 Generalized Contrastive Loss
Generalized Contrastive Loss를 먼저 보기전에 Contrastive Loss function을 먼저 살펴보겠습니다.
τ : margin , margin은 negative pair간의 최소한의 거리를 의미
Distance between representation of input images
d(x_i, x_j) = Euclidean norm이고, Ground Truth (=y)의 값이 1인경우,
(d(xi, xj)^2)/2의 값이 최소화가 되도록 해야한다. 우선 y=1면 두 image가 similar한 경우이기에,
거의 f(xi) == f(xj)하다. 그러기에 Loss의 값은 0에 수렴하게 될 것이다.
Ground Truth (=y)의 값이 0인경우, 아래 그림을 보자
Query image와 Negative image가 주어지면, Negative image는 margin 밖으로 멀어지게 learning이 되어야 한다.
d(xi, xj)의 value가 margin보다 멀리있다면, Negative로 잘 학습이 되고 있다는 것이다.
그러면 식에서 음수 value가 나오게 될 것이고 음수가 나오면 0을 반환을 한다.
그러나 위의 Contrastive Loss function에는 문제가 있다. 아래 3개의 image로 예시를 들어보면,
(A, B) -> Similar (y=1) : A와 B는 동그라미 도형의 유사한 부분이 있기에 1
(B, C) -> Similar (y=1) : B와 C는 세모 모형이 유사한 부분이 있기에 1
(A, C) -> Dissimilar (y=0) : A와 C는 공통적인 모형이 없기 때문에 0
Contrastive Loss(대비 손실) 기능의 최적화는 다음과 같이 유사한 영상 쌍(A, B) 및 (B, C)의 표현 사이의 거리를 최소화하는 것을 목적이다.
그러나, 다음 식을 보자.
위의 식은 A와 B, B와 C의 유클리드 distance가 0에 가깝다 라고 표현할 수 있다.
그렇기에 A와 B, B와 C의 Embedding vector는 거의 동일하다.
이를 삼단 논법으로 보면, 결국 A와 C도 Similar하다는 결론이 나오게 된다.
위의 예에서는 (A, C)는 다른 라벨로 표시되어 있는데, fig 3의 결과는 fig 1이 보장하는 최적화와 대조적이다.
훈련 프로세스의 이러한 불일치는 Contrastive Loss function이 input pair 간의 부분적인 (Continuous) Similar를 고려하지 않기 때문이다.
그러면 이제 Generalized Contrastive Loss Function을 살펴보자.
binary보다는 continuous similar를 표현하는 Contrastive Loss의 일반화 공식을 제안
=> Generalized Contrastive Loss (=GCL)
ψ(i,j) : xi, xj 의 similar의 ground truth, 0 ~ 1까지의 Continuous value (0 or 1이 아닌)
Generalized Contrastive Loss 함수를 최소화함으로써 각 pair의 거리는 대응하는 similar에 비례하여 최적화
GCL 함수를 보면, CL함수와 크게 달라진 점은 ψ의 값이 추가된 것이다.
4 TRAINING DATA AND AUTOMATIC LABELLING
Generalized Contrastive Loss(일반화 대조 손실) function의 optimize는 (0 ~ 1) range에서 정의된 영상 쌍의 Ground Truth Similar에 의존
Image pair의 Similar 정도를 자동으로 Labeling하는 세 가지 방법을 제시
2D Field-of-View overlap은 두 가지 measure로 설명한다.
1) Weak Labeled, Relying on GPS data -> Weak 2D Field-of-View overlap,
2) Strongly Labeled, Relying on 6DoF camera pose -> Strong 2D Field-of-View overlap
4.1 2D Field-of-View overlap
=> 수평면에서의 카메라 시야의 중첩만을 고려
(b) Soft positive match : 같은 위치지만 방향 40°차이
(c) Soft Negative match : 같은 방향, 거리가 다른 경우
4.1.1 Weak 2D Field-of-View overlap
GPS coordinates과 angle 정보를 사용할 수 있는 경우
=> Weak 2D Field-of-View overlap 제시
첫 번째 row은 Query image, 두 번째 row은 map에서 match, 세 번째 row은 estimated 2D FoV overlap
Red -> QR , blue -> map image, 50% 이상이면 positive matching!
4.1.2 Strong 2D Field-of-View overlap
TB-Places dataset 사용
dataset에 image와 함께 6DoF camera pose 정보를 사용할 수 있는 경우
-> Strong 2D Field-of-View overlap을 제시
pose vector로부터 translation vector(t0, t1)와 angle α를 추출
각 이미지에는 매우 정확한 2D FoV를 추정할 수 있는 6DOF 카메라 포즈가 포함
TB-places 데이터 세트의 원본 논문에 따르면, 카메라의 FoV 각도를 90 = 90 µ로, 반지름을 r = 3.5m로 설정
첫 번째 row : 74% positive pair
두 번째 row : 41% Soft negative pair
4.2 3D Field-of-View overlap
7가지 환경에서 촬영한 RGBD image set인 7Scene dataset 사용
3D reconstructure을 사용할 수 있는 경우
각 image는 연관된 6DoF pose를 가지며 각 image의 3D reconstructure가 제공
Point cloud에 6DoF pose와 함께 주어진 image를 projection
Image pair의 경우 두 image와 연관된 3D 지점 세트의 intersection-overunion (IoU)으로 3D FoV overlap을 계산
QR image : red, map : blue, Overlap : magenta
5. Implementation details
5.1 Evaluation metric
6 RESULTS AND DISCUSSION
6.1 Large scale outdoor place recognition
MSLS training set에 관한 몇 가지 모델을 training해, MSLS validation과 test set에 관한 결과를 보고
BackBone : VGG16, ResNet50, ResNet152, ResNeXt101-32x8d
Pooling : global pooling layer, average global pooling
Loss function : binary Contrastive Loss, Generalized Contrastive Loss
BackBone network와 pooling layer의 각 조합에 대해 binary Contrastive Loss, Generalized Contrastive Loss optimize 실행
6.2 Result
GCL function으로 훈련받은 모델이 CL로 훈련받은 모델보다 일관되게 성능이 우수
GCL loss function을 사용하여 training한 convolution backbone과 Siamese Network로 배열된 단순한 pooling layer으로만 구성된 단순한 architecture가 triplet network와 VLAD 계층을 배치하는 것처럼 복잡한 architecture보다 뛰어나다는 것을 입증
7 CONCLUSIONS
Image retrieval 및 visual place recognition을 위해 two-way Siamese Network를 효과적으로 training하기 위한 새로운 Generalized Contrastive Loss function를 제시
이 목적을 위해 우리는 image Similar의 Continuous한 Measure을 정의
GPS와 angle, 6DOF camera pose, image 3D 재구성 등 기하학적 정보를 바탕으로 image pair의 Similar estimated을 위한 자동주석 3가지 방식을 구현
MSLS, TB-Places 및 7Scene dataset를 배치하여 binary label이 아닌 rank별 유사성으로 image pair을 제공 (Positive, Soft Negative, Hard Negative)
Re-annotation process는 자동으로 이루어지므로 사람의 개입이 필요하지 않음
제안된 Generalized Contrastive Loss 함수와 rank별 유사성 labeled set를 사용하여 한 네트워크는 MSLS,
TB-Places 및 7Scene 데이터셋에서 binary Contrastive Loss function로 training받은 network보다 지속적으로 더 높은 결과(상위 5개 리콜 최대 18%)를 달성
'Paper' 카테고리의 다른 글
| [논문 리뷰]Siamese Neural Networks for One-shot Image Recognition (2015) (0) | 2022.03.20 |
|---|