<개인적인 공부를 위해 작성된 글입니다. 오타 혹은 잘못된 부분이 있다면 지적해주시면 감사하겠습니다.>
대학원 생활을 하면서 매주 논문을 찾다보니 머리가 자주 빠지는것 같다.. 교수님들이 왜 머리가 빨리 없어지는지 조금은 알 것 같아..
오늘은 읽어본 논문 중에 오늘은 Siamese Neural Network 라는 내용의 논문에 대해서 리뷰를 해볼 예정이다.
- Abstract
ML의 학습과정은 비용이 많이 들고 데이터가 많이 없는 경우에는 학습하기 어렵다. 그렇기에 머신러닝의 학습과정은 많은 양의 데이터가 필요하고 그에 따른 계산 비용이 발생하기 마련이다. 이 논문에서는 Data가 부족한 상황에서도 좋은 성능을 내기위한 학습기법을 제시하고 있다.
=> One-Shot Learning 기법
One shot learning은 일반적인 machine learning과 다르게 한 class당 한 개의 예시만 주어져 있는 상태에서 test에 대한 예측을 수행해야 하는 상황을 의미
여기서 쓰이는 학습은 One-Shot Learning 기법을 이용하고 유사성을 매기기위한 구조로 input들 간 similarity를 계산하는 siamese neural network를 제시한다. 이 네트워크는 적은 양의 데이터에 대해 정확한 예측을 가능하게 한다. 또한 새로운 class에 대해서도 정확한 예측을 할 수 있도록 한다.
1. Approach
Siamese Neural Network으로 supervised metric based 접근방식을 통해서 image representation을 학습하고 다시 훈련할 필요없이 Network's feature를 통해 One-shot learning이 가능하다.
<논문에서 제시한 Strategy>
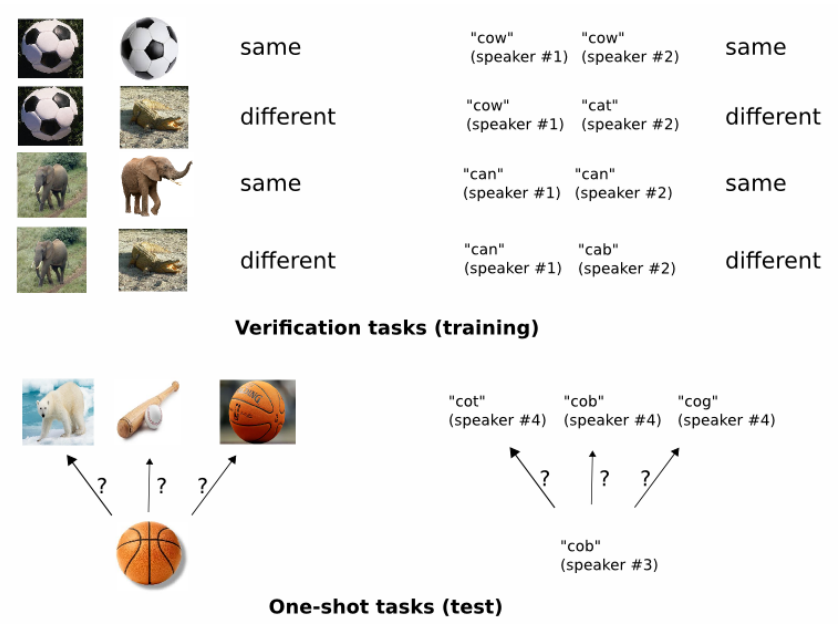
1) 동일 or 다른 pair의 집합을 구별할 수 있도록 model을 훈련시킨다.
2) 학습된 feaeture mapping 기반으로 새로운 categories을 평가하여 검증한다.
이 논문에서는 문자 인식에 attention을 제한하고 있으나 다른 종류에도 사용가능하다. 또한 General strategy의 사용되는 도메인을 위해서, Siamese NN을 사용하며 아래와 같은 특징을 가지고 있다.
a) 일반적인 이미지 feature을 학습 가능하며, 새로운 class 분포에 대한 예측이 가능
b) source data에서 sampling된 pair에 대한 최적화 기법을 사용해서 쉽게 훈련이 가능
c) Deep learning 기술을 활용하여 domain-specifi knowledge에 의존하지 않고 경쟁력 있는 접근 방식을 제공
one-shot image 분류 모델을 개발하기 위해 image pair의 class id를 구별할 수 있는 신경망 학습을 목표
학습 방법은 두 개의 input을 넣었을때 두 input이 같은 class인지 다른 class인지 labeling을 해준다.
즉, 두 개의 이미지를 보여주면 same, different를 output으로 내는 모델을 학습하는 것
2. Related Work
크게 중요한 keyword가 없어 우선 pass
3. Deep Siamese Networks for Image Verification
Siamese Network은 1990년대 초 브롬리와 르쿤이 image matching 문제로 signature verification을 해결하기 위해 처음 도입했다고 한다.
Siamese Network는 2개의 다른 input을 받아들이지만 상단의 function에 의해 결합되는 twin 네트워크로 구성된다. symmetic한 특징으로 input을 반대로 넣어도 같은 결과를 가져온다.
이 function는 각 측면에서 가장 높은 수준의 feature representation 사이의 일부 metric을 계산 (fig.3)
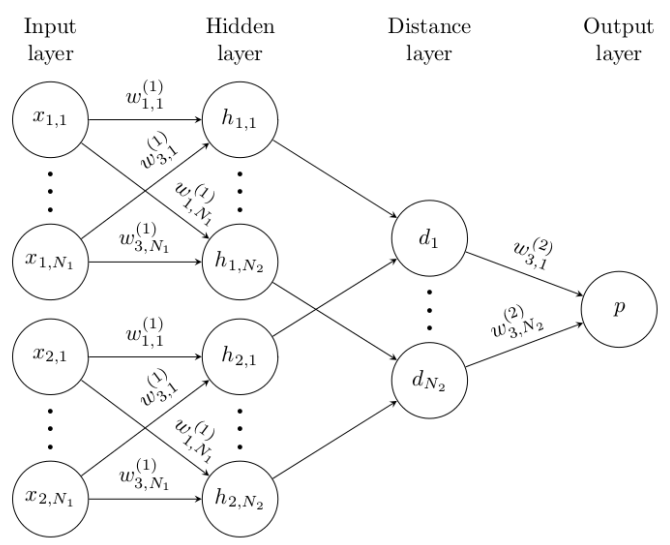
=> Network 구조는 상단과 하단섹션이 복제되어 Twin Network를 형성하며 각 계층에 공유 weight metric가 존재
input image가 pair로 존재하기 때문에 각각의 이미지를 sub network에 넣어 output 두 개를 만들고 두 output을 통해 distance를 산출
이 논문에서는 sigmoid activation function와 결합하며 0 혹은 1의 output을 내고, twin feature vector h1, h2 사이의 거리를 L1 Distance를 통해 구한다. (0은 different 1은 same이다.)
따라서 네트워크를 훈련하기 위해 loss function으로 cross-entropy objective를 선택한다.
대규모 convolution network를 구축하기 위해 CUDA Library를 사용가능하다.
이제 Siamese net의 구조와 experiment에 사용된 학습 알고리즘의 세부 사항을 모두 자세히 설명한다.
3.1. Model
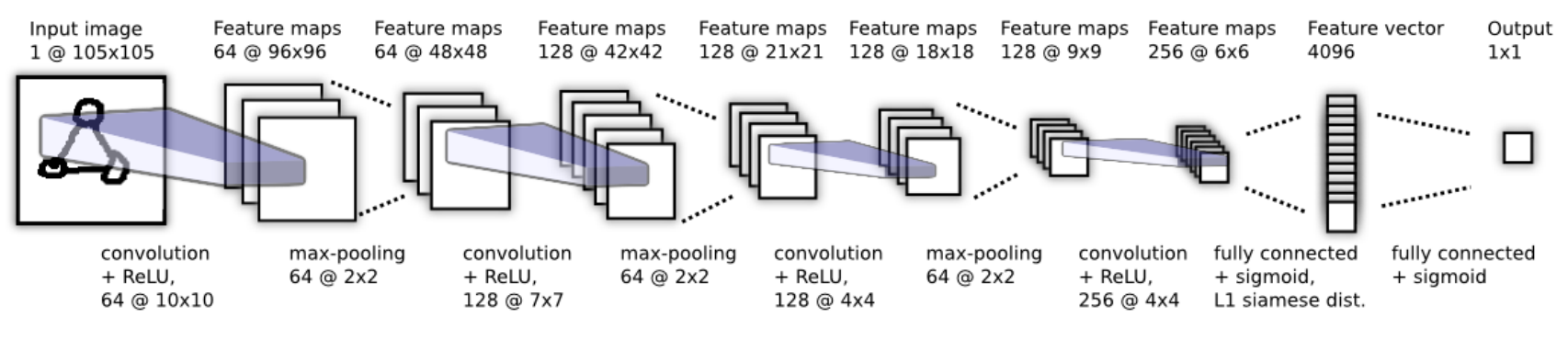
(verification task을 위한 Best convolution architecture)
Siamese net은 묘사되진 않았지만, 4096 unit fc layer에서 vector 사이의 L1 distance 계산 후 결합된다.
Standard model은 L layer과 N_l를 가진 siamese convolutional neural network이다. 여기서 h1_l은
여기서 h1_l은 첫 번째 쌍둥이 layer l의 hidden vector를 나타내고, h2_l은 두 번째 쌍둥이 layer의 hidden vector를 말한다.
첫 L-2 layer에서는 ReLU를, 나머지 layer에서는 sigmoidal unit을 사용한다.
이 model은 convolution layer의 sequence로 이루어져 있으며, 각 layer는 크기가 다양한 filter와 stride는 1로 고정된 single channel을 사용한다.
성능을 최적화하기 위해서 convolution filter의 수를 16의 배수로 지정한다. 옵션으로 filter 크기와 stride가2인 max-pooling도 사용한다.
따라서 각 layer의 k번째 filter map은 다음 형식을 따른다.
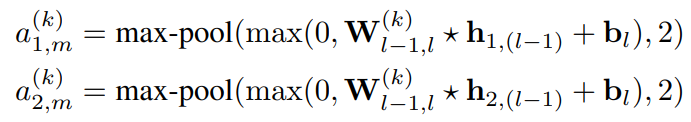
은 여기서 layer l의 feature map을 나타내는 3차원 tensor이며, 각 convolution filter와 input feature map 사이의 overlap의 결과인 valid convolutional operation이 되도록 하였다
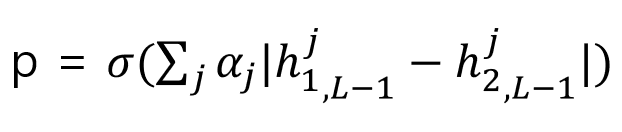
The unit of final convolutional layer는 flatten to single vector가 된 후, 아래와 같이 distance를 구한다.
The unit of final convolutional layer는 single vector로 flatten되는데, 위와같이 distance metric을 계산하고, 이는 Sigmoid에 output으로 주어진다.
σ는 sigmoidal function을 사용한다는 것이고,j번째일때 첫 번째 image의 feature vector와 두 번째 image의 feauture vector끼리 L-1 distance를 구하고 parameter α를 곱해서 probability를 구한다. α는 weight으로 학습에 의해 update 되는 parameter이다.
3.2. Learning
Loss function
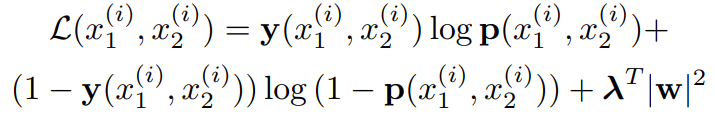
M은 minibatch size를 나타낸다. i는 minibatch를 인덱스로 나누는 것을 의미함.
동일한 문자 class일 경우 => y(x_1^(i), x_2^(i)) = 1
다른 문자 class 일 경우 => y(x_1^(i), x_2^(i)) = 0
loss function은 이진 분류 regularized cross-entropy를 사용한다.
Optimization
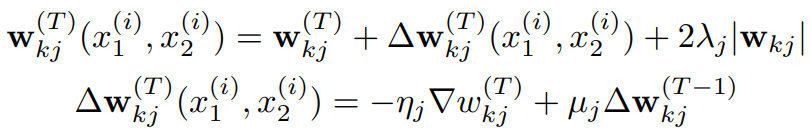
표준 backpropagation 알고리즘과 결합, Momentum GD, minibatch size 128, epoch T에서 업데이트 규칙은 위의 식과 같다.
4. Experiments
Omniglot dataset으로 model을 학습 후, one-shot performance와 verification 에 대한 상세 정보 제공
4.1. The Omniglot Dataset
손으로 쓴 문자 인식 domain의 몇 가지 예로부터 학습하기 위한 표준 벤치마크를 위해 작성
-> 국제 알파벳 50개의 예가 포함 (라틴어, 한국어, Aurek-Besh 및 Klingon 가상 문자 집합 포함 등등)

알파벳 글자 수는 15~40자 이상으로 다양하다.
50개의 알파벳을 40 alphabet background set과 10 alphabet evaluation set으로 나누고,
background set은 hyperparameter를 학습해 model을 develop하는 데 쓰이고, evaluation set은 one-shot classification performance를 평가하는 데에만 쓰인다
verification network를 훈련하기 위해 30k, 90k, 150k의 data를 동일하거나 다른 임의의 pair로 샘플링 후 사용했다.
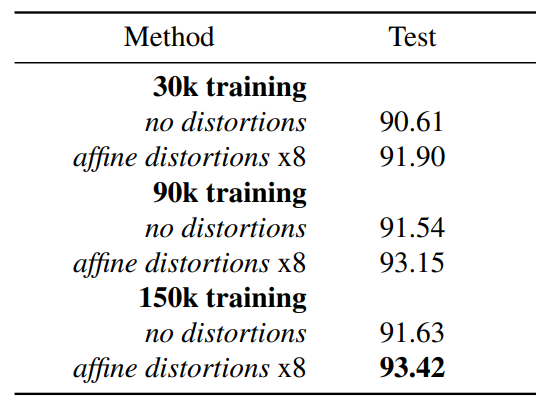
training performance를 확인하기 위해 두 가지 전략을 사용
1. 10개의 알파벳과 4개의 additional drawers에서 추출한 10,000개의 sample pair로 검증을 위한 검증 세트를 작성
2. 동일한 알파벳과 drawer를 활용하여 평가 세트의 대상 작업을 모방하는 검증 세트에 대한 320개의 one-shot recognition set를 생성
5. Conclusions
검증을 위해 심층 컨볼루션 샴 신경망을 먼저 학습하여 원샷 분류를 수행하는 전략을 제시하고 네트워크의 성능을 Omniglot dataset 용으로 개발된 기존의 최첨단 분류기와 비교한 새로운 결과의 개요를 설명
다음엔 Siamese NN와 관련된 논문에 대해서 더 찾아볼 예정이다.
'Paper' 카테고리의 다른 글
| [논문 리뷰] Generalized Contrastive Optimization of Siamese Networks for Place Recognition (2021) (0) | 2022.03.22 |
|---|
<개인적인 공부를 위해 작성된 글입니다. 오타 혹은 잘못된 부분이 있다면 지적해주시면 감사하겠습니다.>
대학원 생활을 하면서 매주 논문을 찾다보니 머리가 자주 빠지는것 같다.. 교수님들이 왜 머리가 빨리 없어지는지 조금은 알 것 같아..
오늘은 읽어본 논문 중에 오늘은 Siamese Neural Network 라는 내용의 논문에 대해서 리뷰를 해볼 예정이다.
- Abstract
ML의 학습과정은 비용이 많이 들고 데이터가 많이 없는 경우에는 학습하기 어렵다. 그렇기에 머신러닝의 학습과정은 많은 양의 데이터가 필요하고 그에 따른 계산 비용이 발생하기 마련이다. 이 논문에서는 Data가 부족한 상황에서도 좋은 성능을 내기위한 학습기법을 제시하고 있다.
=> One-Shot Learning 기법
One shot learning은 일반적인 machine learning과 다르게 한 class당 한 개의 예시만 주어져 있는 상태에서 test에 대한 예측을 수행해야 하는 상황을 의미
여기서 쓰이는 학습은 One-Shot Learning 기법을 이용하고 유사성을 매기기위한 구조로 input들 간 similarity를 계산하는 siamese neural network를 제시한다. 이 네트워크는 적은 양의 데이터에 대해 정확한 예측을 가능하게 한다. 또한 새로운 class에 대해서도 정확한 예측을 할 수 있도록 한다.
1. Approach
Siamese Neural Network으로 supervised metric based 접근방식을 통해서 image representation을 학습하고 다시 훈련할 필요없이 Network's feature를 통해 One-shot learning이 가능하다.
<논문에서 제시한 Strategy>
1) 동일 or 다른 pair의 집합을 구별할 수 있도록 model을 훈련시킨다.
2) 학습된 feaeture mapping 기반으로 새로운 categories을 평가하여 검증한다.
이 논문에서는 문자 인식에 attention을 제한하고 있으나 다른 종류에도 사용가능하다. 또한 General strategy의 사용되는 도메인을 위해서, Siamese NN을 사용하며 아래와 같은 특징을 가지고 있다.
a) 일반적인 이미지 feature을 학습 가능하며, 새로운 class 분포에 대한 예측이 가능
b) source data에서 sampling된 pair에 대한 최적화 기법을 사용해서 쉽게 훈련이 가능
c) Deep learning 기술을 활용하여 domain-specifi knowledge에 의존하지 않고 경쟁력 있는 접근 방식을 제공
one-shot image 분류 모델을 개발하기 위해 image pair의 class id를 구별할 수 있는 신경망 학습을 목표
학습 방법은 두 개의 input을 넣었을때 두 input이 같은 class인지 다른 class인지 labeling을 해준다.
즉, 두 개의 이미지를 보여주면 same, different를 output으로 내는 모델을 학습하는 것
2. Related Work
크게 중요한 keyword가 없어 우선 pass
3. Deep Siamese Networks for Image Verification
Siamese Network은 1990년대 초 브롬리와 르쿤이 image matching 문제로 signature verification을 해결하기 위해 처음 도입했다고 한다.
Siamese Network는 2개의 다른 input을 받아들이지만 상단의 function에 의해 결합되는 twin 네트워크로 구성된다. symmetic한 특징으로 input을 반대로 넣어도 같은 결과를 가져온다.
이 function는 각 측면에서 가장 높은 수준의 feature representation 사이의 일부 metric을 계산 (fig.3)
=> Network 구조는 상단과 하단섹션이 복제되어 Twin Network를 형성하며 각 계층에 공유 weight metric가 존재
input image가 pair로 존재하기 때문에 각각의 이미지를 sub network에 넣어 output 두 개를 만들고 두 output을 통해 distance를 산출
이 논문에서는 sigmoid activation function와 결합하며 0 혹은 1의 output을 내고, twin feature vector h1, h2 사이의 거리를 L1 Distance를 통해 구한다. (0은 different 1은 same이다.)
따라서 네트워크를 훈련하기 위해 loss function으로 cross-entropy objective를 선택한다.
대규모 convolution network를 구축하기 위해 CUDA Library를 사용가능하다.
이제 Siamese net의 구조와 experiment에 사용된 학습 알고리즘의 세부 사항을 모두 자세히 설명한다.
3.1. Model
(verification task을 위한 Best convolution architecture)
Siamese net은 묘사되진 않았지만, 4096 unit fc layer에서 vector 사이의 L1 distance 계산 후 결합된다.
Standard model은 L layer과 N_l를 가진 siamese convolutional neural network이다. 여기서 h1_l은
여기서 h1_l은 첫 번째 쌍둥이 layer l의 hidden vector를 나타내고, h2_l은 두 번째 쌍둥이 layer의 hidden vector를 말한다.
첫 L-2 layer에서는 ReLU를, 나머지 layer에서는 sigmoidal unit을 사용한다.
이 model은 convolution layer의 sequence로 이루어져 있으며, 각 layer는 크기가 다양한 filter와 stride는 1로 고정된 single channel을 사용한다.
성능을 최적화하기 위해서 convolution filter의 수를 16의 배수로 지정한다. 옵션으로 filter 크기와 stride가2인 max-pooling도 사용한다.
따라서 각 layer의 k번째 filter map은 다음 형식을 따른다.
은 여기서 layer l의 feature map을 나타내는 3차원 tensor이며, 각 convolution filter와 input feature map 사이의 overlap의 결과인 valid convolutional operation이 되도록 하였다
The unit of final convolutional layer는 flatten to single vector가 된 후, 아래와 같이 distance를 구한다.
The unit of final convolutional layer는 single vector로 flatten되는데, 위와같이 distance metric을 계산하고, 이는 Sigmoid에 output으로 주어진다.
σ는 sigmoidal function을 사용한다는 것이고,j번째일때 첫 번째 image의 feature vector와 두 번째 image의 feauture vector끼리 L-1 distance를 구하고 parameter α를 곱해서 probability를 구한다. α는 weight으로 학습에 의해 update 되는 parameter이다.
3.2. Learning
Loss function
M은 minibatch size를 나타낸다. i는 minibatch를 인덱스로 나누는 것을 의미함.
동일한 문자 class일 경우 => y(x_1^(i), x_2^(i)) = 1
다른 문자 class 일 경우 => y(x_1^(i), x_2^(i)) = 0
loss function은 이진 분류 regularized cross-entropy를 사용한다.
Optimization
표준 backpropagation 알고리즘과 결합, Momentum GD, minibatch size 128, epoch T에서 업데이트 규칙은 위의 식과 같다.
4. Experiments
Omniglot dataset으로 model을 학습 후, one-shot performance와 verification 에 대한 상세 정보 제공
4.1. The Omniglot Dataset
손으로 쓴 문자 인식 domain의 몇 가지 예로부터 학습하기 위한 표준 벤치마크를 위해 작성
-> 국제 알파벳 50개의 예가 포함 (라틴어, 한국어, Aurek-Besh 및 Klingon 가상 문자 집합 포함 등등)
알파벳 글자 수는 15~40자 이상으로 다양하다.
50개의 알파벳을 40 alphabet background set과 10 alphabet evaluation set으로 나누고,
background set은 hyperparameter를 학습해 model을 develop하는 데 쓰이고, evaluation set은 one-shot classification performance를 평가하는 데에만 쓰인다
verification network를 훈련하기 위해 30k, 90k, 150k의 data를 동일하거나 다른 임의의 pair로 샘플링 후 사용했다.
training performance를 확인하기 위해 두 가지 전략을 사용
1. 10개의 알파벳과 4개의 additional drawers에서 추출한 10,000개의 sample pair로 검증을 위한 검증 세트를 작성
2. 동일한 알파벳과 drawer를 활용하여 평가 세트의 대상 작업을 모방하는 검증 세트에 대한 320개의 one-shot recognition set를 생성
5. Conclusions
검증을 위해 심층 컨볼루션 샴 신경망을 먼저 학습하여 원샷 분류를 수행하는 전략을 제시하고 네트워크의 성능을 Omniglot dataset 용으로 개발된 기존의 최첨단 분류기와 비교한 새로운 결과의 개요를 설명
다음엔 Siamese NN와 관련된 논문에 대해서 더 찾아볼 예정이다.
'Paper' 카테고리의 다른 글
| [논문 리뷰] Generalized Contrastive Optimization of Siamese Networks for Place Recognition (2021) (0) | 2022.03.22 |
|---|